Bevy is an open-source game engine built with Rust. It uses the Entity Component System (ECS) paradigm to simplify building performant parallel games.
When building games dealing with large numbers of entities in parallel, performance problems are common.
I have recently encountered these problems with rustcraft, a voxel project that I’m now building with Bevy. Read A Minecraft Experiment with Rust and OpenGL for more details on that.
This is a short introduction to tracing and how it can be used to track down and fix performance problems in your Bevy project. Bevy also has official documentation on profiling, so don’t forget to read that too.
What is tracing?
Tracing, and particularly distributed tracing, is an important pillar of observability. It provides insight into where the bottlenecks are inside code or a distributed system.
A trace is effectively a nested structure of events detailing what goes on inside a system.
These events are known as spans. At the very least spans will have a name and duration, but other metadata can be attached too.
A trace of a customer’s order at a restaurant might look something like this:
trace_id: order1234
|- order_food 5 min
|--- decide_order 5 min
|----- decide_drink 1 min
|----- decide_food 4 min
|- wait_for_waiter 30 min
|- place_order 2 min
|--- send_order_to_kitchen 1 min
|- cook_order 15 min
|- deliver_order 3 min
The entire trace has a unique ID order1234 and its spans like decide_order and send_order_to_kitchen have a duration attached.
It is easy to see that the bottleneck in this particular order is its slow service, with a 30 min wait!
Tracing in Bevy
Bevy is of course a game engine, not a restaurant. So how does tracing work there?
Many aspects of the engine are instrumented by default with Rust’s tracing crate. That means spans are automatically created when different parts of the engine’s code are entered.
Systems are included in that, meaning that with tracing enabled it is possible to break down the processing inside individual frames and identify bottlenecks.
On top of the default instrumentation, developers can instrument their own code for much finer detail.
Enabling tracing
To enable tracing on a Bevy project, enable the trace feature in Cargo.toml.
bevy = { version = "0.13.2", features = ["trace"] }
Then choose a tracing backend when running a project.
cargo run --release --features bevy/trace_chrome
There are a few backends to choose from, but this post focuses on trace_chrome.
Using trace_chrome
After running a project with trace_chrome enabled, a JSON file will be output to the local directory.
This file contains all the traces exported from the process and can get very large. For scale, running rustcraft for around 15 seconds produces just over 1GB of trace data.
The file can be opened in Perfetto, a browser-based visualisation tool for Chrome traces. The interface may seem overwhelming, but the main part to focus on is the timeline.
Zooming in all the way, it is easy to see the processing that makes up each individual update:
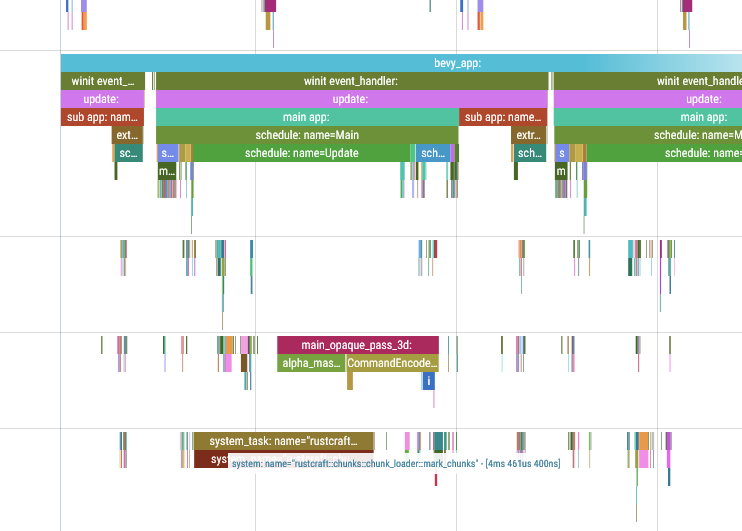
In this trace, I have highlighted a span for the mark_chunks system that shows the duration as 4ms.
The whole Update schedule takes 5ms, so this single system takes up most of the processing and clearly needs optimisation.
Adding custom spans
Complex code doesn’t stop at the system level.
To get more use out of tracing, instrument your own code. Add the #[tracing::instrument] macro to functions, and they’ll start emitting spans.
#[tracing::instrument]
fn my_function() {
do_stuff();
}
For a little more control over the span, create it manually:
fn my_function() {
let _ = info_span!("my_function").entered();
do_stuff();
}
The span will end when the anonymous variable is dropped.
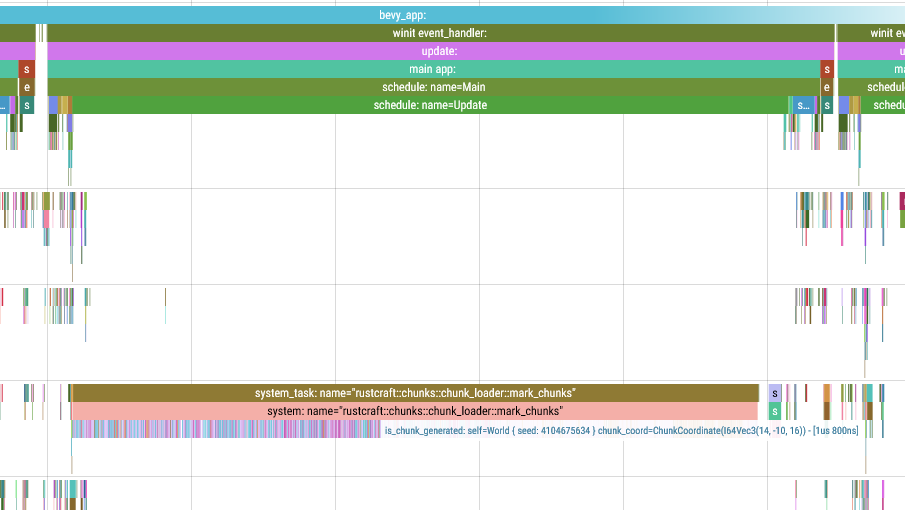
In the example above, I have instrumented the is_chunk_generated function and it’s obvious the mark_chunks system calls it far too often.
Tip
Use custom instrumentation sparingly as it can drastically increase the size of trace data. Log levels can help here.
Aggregating spans
When analysing Bevy trace data, you get many spans across many frames. Visualising on a timeline isn’t always the right answer with such a vast amount of data.
Perfetto lets you run SQL queries over traces, which is incredibly useful for picking out slow running systems.
The following query outputs the top 10 longest running rustcraft systems by average duration.
select
name, (avg(dur) / 1000000) as dur_ms
from
slice
where
name like 'system: name="rustcraft%"'
group by name
order by dur_ms desc
limit 10;
# Results:
# system: name="rustcraft::chunks::chunk_loader::mark_chunks" 9.993739583333333
# system: name="rustcraft::setup_scene" 8.5999
# system: name="rustcraft::chunks::chunk_loader::gather_chunks" 0.5117833333333334
# system: name="rustcraft::chunks::chunk_loader::generate_chunks" 0.34596944444444444
# system: name="rustcraft::chunks::chunk_loader::load_chunks" 0.11756736111111112
# system: name="rustcraft::chunks::chunk_loader::unload_chunks" 0.02262986111111111
# system: name="rustcraft::player::player_move" 0.004745138888888889
# system: name="rustcraft::player::player_look" 0.004228125
That’s better for an overview of my own code’s performance.
mark_chunks still needs some work!